
They look the same. Honestly, when I was researching them, I thought they were the same feature but just different implementations.
You will get the most of out this article if you’re already familiar with BigQuery (BQ) and dbt. In short, the former is a cloud data warehouse and the latter is a data transformation tool that can run on the majority of data warehouses.
A look into history
Bigquery Snapshots
In 2021, Google released a feature called table snapshots for their BigQuery product, you can read more about the release blog here.
“But making mistakes in your enterprise data warehouse, such as accidentally deleting or modifying data, can have a major impact on your business.”
…
“you may want to maintain the state of your data beyond the 7 day window, for example, for auditing or regulatory compliance requirements”
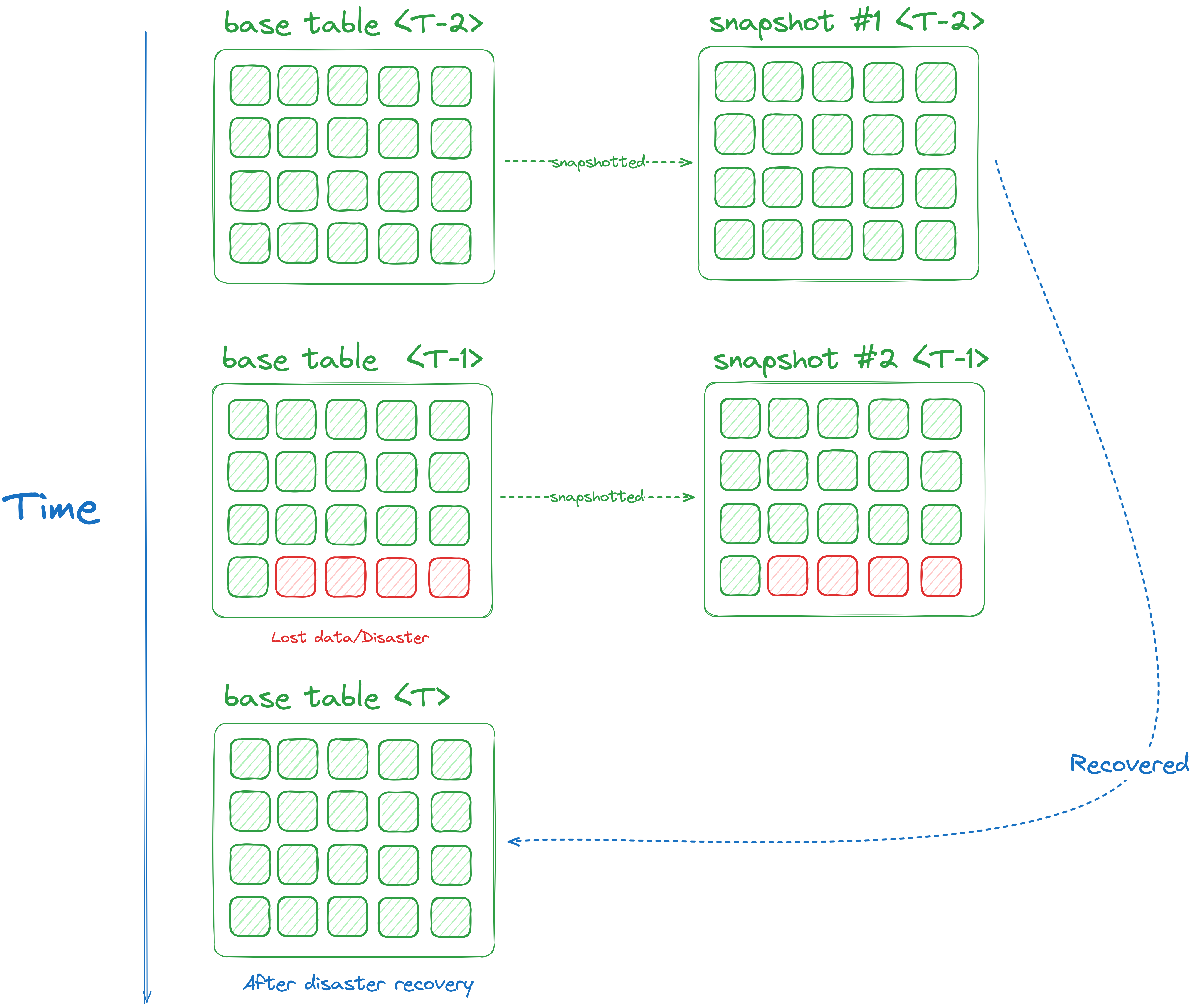
Essentially, BQ Snapshots are for "backup and disaster recovery”, especially for data that’s over the 7 days of the default Time Travel, which is another BQ feature but we won’t cover that in this article.
dbt Snapshots
Not many people know this, but back in v0.5.1 (released in 2016), dbt Labs released a feature called Source table archive which later became Snapshots in v0.14 released in 20191.
From the original description of Source table archive
The archived tables will mirror the schema of the source tables they're generated from. In addition, three fields are added to the archive table: valid_from, valid_to, …
Sounds familiar? Yes, this is dbt’s implementation of SCD2 tables. And there’s no mention of data backup here.

Now let’s look at how you can actually create these.
Creation
For simplicity’s sake, I’ll use dbt on top of BQ as well since it can’t function alone. dbt offers a free solution called dbt Core and GCP has a free tier for their BQ. We won’t dive into the initial setup in this article but there’s a very helpful Quickstart by dbt Labs here.
Now, we need a sample table. We can leverage BigQuery Public Dataset for this. Let’s use the orders table in thelook_ecommerce dataset. Start by creating a new dataset and clone the said table.
# create new dataset
create schema snapshot_demo;# clone the public table to our newly created dataset
create or replace table snapshot_demo.orders_base
as
select * from `bigquery-public-data.thelook_ecommerce.orders`
;# preview
select *
from `snapshot_demo.orders_base`
limit 10
;

BigQuery Snapshots
For BQ snapshot, you can easily create its snapshot with just a SQL DML statement.2
# create a snapshot called `orders_snapshot_20240319` in the same dataset as the `orders_base` table
create snapshot table snapshot_demo.orders_snapshot_20240319
clone snapshot_demo.orders_base
;Other than a few visual cues in how it’s displayed in the project structure, you can use BQ Snapshots just like any other native tables in queries.

Say in a disaster, somehow your base table is deleted.3
drop table `snapshot_demo.orders_base`;Querying the snapshot will work regardless. And you can recover the base table from the snapshot as well. Here’s an example using SQL statement.
create or replace table `snapshot_demo.orders_base`
clone `snapshot_demo.orders_snapshot_20240319`
;dbt Snapshots
Now we turn our attention to dbt.
dbt’s first-class citizen is the SQL model, ie. a .sql file, which is materialised as a table in the data warehouse, and to create a snapshot you’ll just need to tweak the configuration for a bit.
Let’s set up a simple model that is a 1-1 view to our order_base table.
#orders_base.sql
select *
from `snapshot_demo.orders_base`The above model essentially creates a new table that’s identical to our base table, but we don’t want that. Let’s tweak it up a bit to have it as a snapshot model instead. Create a new sql file in snapshots/orders_snapshot_dbt.sql
#orders_snapshot_dbt.sql
{% snapshot orders_snapshot_dbt %}
{{
config(
target_schema='snapshot_demo',
unique_key='order_id',
strategy='check',
check_cols = 'all'
)
}}
select *
from `snapshot_demo.orders_base`
{% endsnapshot %}The first time we run dbt snapshot, it will create a new native table orders_snapshot_dbt in the same dataset. With some additional columns


Our dbt Snapshot is a typical SCD2 table with valid_from and valid_to fields. Behind the scenes, it’s no different from the base table. dbt provides us with a very convenient way of creating SCD2 tables with just a few lines of code.
A quick recap
✅ Both BQ and dbt require a base table to create a Snapshot from
✅ BQ Snapshots are represented somewhat differently compared to the base tables
✅ dbt Snapshot is a simple and plain native table with some characteristics of the SCD2 table.
But we don’t just run these once and leave it there no?
Continued usage
What happens if you run BQ and dbt snapshots multiple times then?
If we run the same snapshot creation SQL twice, BQ will return an error
Already Exists: Table snapshot_demo.orders_snapshot_20240319Not too surprising, we do have to maintain different names for different snapshots.
Let’s create a differently named snapshot, but this time we’re going back to the future
create snapshot table snapshot_demo.orders_snapshot_20240320
clone snapshot_demo.orders_base
;

A nice added benefit of creating and maintaining these BQ snapshots with a date suffix is that BigQuery automatically picks up on the pattern and groups them together, which makes for a well-structured dataset.
Most backup strategies will require the backup process to run multiple times. This can get messy really quickly if there’s no convention within the team on how to organise these backup assets.
And of course, this feature extends to native tables as well.
As for dbt, an SCD2 table is for tracking changes, so now let’s introduce a few changes to our base table
update snapshot_demo.orders_base
set status = 'Cancelled'
where order_id = 16
;
Now, re-running the dbt snapshot process also introduces some new updates to our dbt snapshot table.
select
order_id, status
dbt_scd_id,
dbt_updated_at,
dbt_valid_from,
dbt_valid_to,
from `joon-sandbox.snapshot_demo.orders_snapshot_dbt`
where order_id = 16
When re-running dbt snapshot, we don’t get a new table, instead old records are updated and new records are inserted in the same snapshot.
To modify or to not modify?
You might notice that I use the terms native table and snapshot to describe the characteristics of BQ and dbt Snapshots. There’s a reason for it.
If we try and perform the same update earlier but to a BQ Snapshot
update snapshot_demo.orders_snapshot_20240319
set status = 'Cancelled'
where order_id = 16
;
Evidently, we cannot make changes to a BQ snapshot once it is created.
Performing the same update on a dbt Snapshot
update snapshot_demo.orders_snapshot_dbt
set status = 'Cancelled'
where order_id = 16
;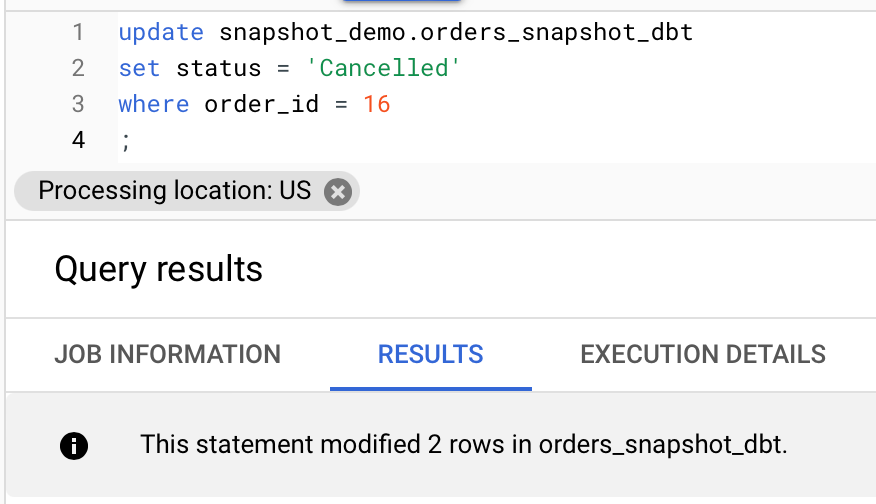
Now what does this little experiment tell us?
If we are using BQ Snapshots for backup, we can leverage the built-in immutability to safeguard against any accidental human errors. Achieving the same benefit with dbt Snapshots would require us to spend some extra effort on maintaining permission and access policies. This is a fundamental difference between a BQ native table and a BQ snapshot.
I’ve seen more than once data teams evaluate dbt Snapshots as a potential backup tool. It does the job, but it’s not the feature that the original creator intended. Something creative usage of a tool can bring about significant technical debts down the line.
A note on storage
Well now, for BQ Snapshots, you would have to maintain potentially hundreds of snapshots, what makes it stand out compared to just creating say, native tables then?
It all comes down to storage.

Storage costs apply for table snapshots, but BigQuery only charges for the data in a table snapshot that is not already charged to another table
This means you’d pay less for 100 snapshots compared to 100 native tables in BigQuery. Considering the frequency with which data teams run their backup and the number of tables being processed each time. A huge incentive for teams to switch to BigQuery Snapshots for their backup strategy.
In theory, this plays out quite well, but also, BQ is what is considered a columnar storage, ie if you query a column from a table with filters applied, you get charged as if you query without regardless.
# these two queries got charged the same amount, given that caching is off
select order_id from orders_base;
select order_id from orders_base where order_id < 100;This leads to my hypothesis that if you change just one row in the base table but across all columns and create a snapshot off of it, you will be charged as if you maintain a duplicate of the base table, ie. a native table.
As of now, according to the official documents, there’s no direct way of calculating the differential storage and cost of a BigQuery Snapshot yet.

As noted above, dbt Snapshot is essentially a native table, and you get to see the real storage usage as well as the associated cost of it.
Recap
I hope this piece has been informative, more so than the feature names we’ve reviewed so far.
All in all, they are different tools, deployed for different use cases. You can always go with both.
I will leave you with this piece of tldr sketch, a summary of this article so far.

Thank you for reading!
Share it with your team to save you 5+ hours of researching and writing!
If you want to see more content like this, consider subscribing to this newsletter as well!
References
Yes, I’m a history buff and I like scrolling through release notes of software like a madman.
Besides SQL statements, snapshots can be created using the BigQuery UI, bq CLI, and API as well.
Might be redundant, but please don’t do this in production.